Record Linkage Graphical User Interfaces
Manual handling of duplicates in a database can be quite time consuming. It is important to find the right tool to help you speed this process. Or if you are building your own record linkage tool, it is always good to see what is out there, how GUIs are laid out and what the common features are.
The Link King:
The Link King’s graphical user interface (GUI) makes record linkage and unduplication easy for beginning and advanced users. The data linking neophyte will appreciate the easy-to-follow instructions. The Link King's artificial intelligence will assist in the selection of the most appropriate linkage/unduplication protocol.
Linkage Wiz:
TAILOR -
LinkageWiz is a powerful data matching and record de-duplication software program used by businesses, government agencies, hospitals and other organisations in the USA, Canada, UK, Australia and France. It makes it easy to link records across multiple databases and to identify and remove duplicate records within databases
TAILOR is extensible, and hence any proposed searching method, comparison function, decision model, or measurement tool can be easily plugged into the system. We have proposed three machine learning record linkage models that raise the limitations of the existing record linkage models. Our extensive experimental study, using both synthetic and real data, shows that the machine learning record linkage models outperform the probabilistic record linkage model with respect to the accuracy and the completeness metrics, the probabilistic record linkage model identifies a lesser percentage of possibly matched record pairs, both the clustering and the hybrid record linkage models are very useful, especially in the case of real applications where training sets are not available or are very expensive to obtain, and Jaro's algorithm performs better than the other comparison functions.
The following three screen snapshots are the basic screens of TAILOR graphical user interface. The first screen allows the user to either generate a synthetic experiment using DBGen, perform a real experiment on a database, or repeat a previous experiment knowing its data files. The user then uses the second screen in order to select a searching method and a comparison function and tune their required parameters. Finally, the third screen allows the user to select the decision model he would like to apply and outputs the values of the measures if the experiment is on synthetic data.
Download PDF for screenshots of TAILOR here.
MatchIT -
matchIT incorporates our proprietary matching algorithms to ensure phonetic, miskeyed and abbreviated variations of data are detected. Results can be verified using comprehensive data auditing functions, drilling down to suspect data, identifying data anomalies, and filtering garbage and salacious words.

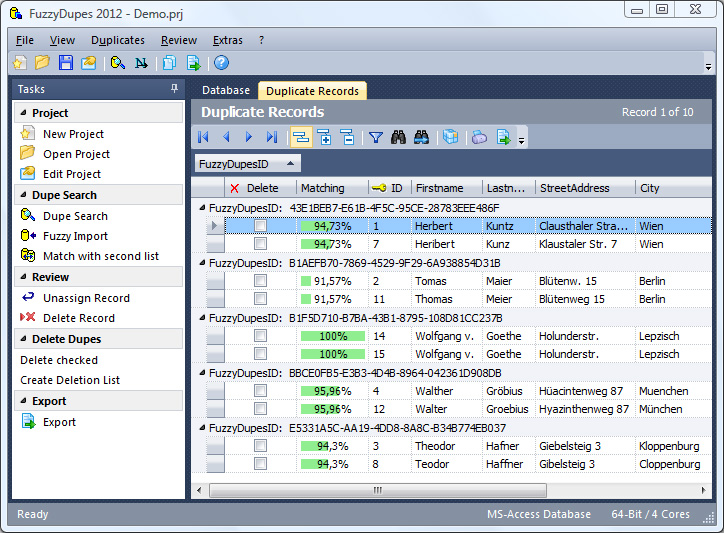
Fuzzy Dupes 2007
Did you know that your contact database typically contains 3-10% duplicates ?
These duplicate records result in unnecessary costs when sending out printed catalogs, are aggravating to your customers, create problems in the controlling, etc. With classical methods you have no possibility to locate these duplicates in your database.